FrameMaker 変換表
当然ながらFrameMakerのヘルプトピックに変換表の記事がありますので開いてみます。
変換処理では、FrameMaker 書式コンポーネント(段落タグ、文字タグ、マーカー、相互参照、表コンポーネントなど)から、構造化エレメントを作成します。
FrameMaker (2017 release) ヘルプ から引用
その通りですね。「変換処理」とは非構造化文書を構造化文書にする処理ですから、まず非構造化文書を開きます。その非構造化文書は、
変換処理を開始するには、内容を代表するような非構造化文書を選択します。 この文書には、文書に出現しうるあらゆる書式タグの例が含まれていることが理想的です。
FrameMaker (2017 release) ヘルプ から引用
そうです。「内容を代表するような、文書に出現しうるあらゆる書式タグの例が」含まれている文書を変換前文書として選択します。
選択します、といっても「文書に出現しうるあらゆる書式タグ」が網羅されている文書ファイルが存在し且つそれをすぐ選択できる状況は稀ではないでしょうか。
ということで、出来るだけ全文書(構造化すべきブック内全コンポーネント)を通して出現しうるあらゆる書式タグのうち、全書式タグを使用していなくても最も多いであろう文書を選択します。
つまり、この時点でFrameMaker書式コンポーネント(上記参照、Adobe談)について適切に管理されていることが望ましいといえます。
しかし待ってください。そんなことってあるでしょうか?
わが組織の既存文書の書式コンポーネントはすべて適切に管理され、登録されていない段落タグ(段落書式)などなく、書式の上書き(オーバーライド)も皆無で、適切な個所に適切なタグが設定されているのは間違いない!!
という方は、問題ないです。失礼しました。
往々にして歴史のある文書には様々な理由で様々な書式が入り乱れているのが普通だと思っています。
書式は入り乱れているのに表示(見栄え)だけは統一されている場合はオーバーライドされている可能性が高いですよね。
次の画像をご覧ください。
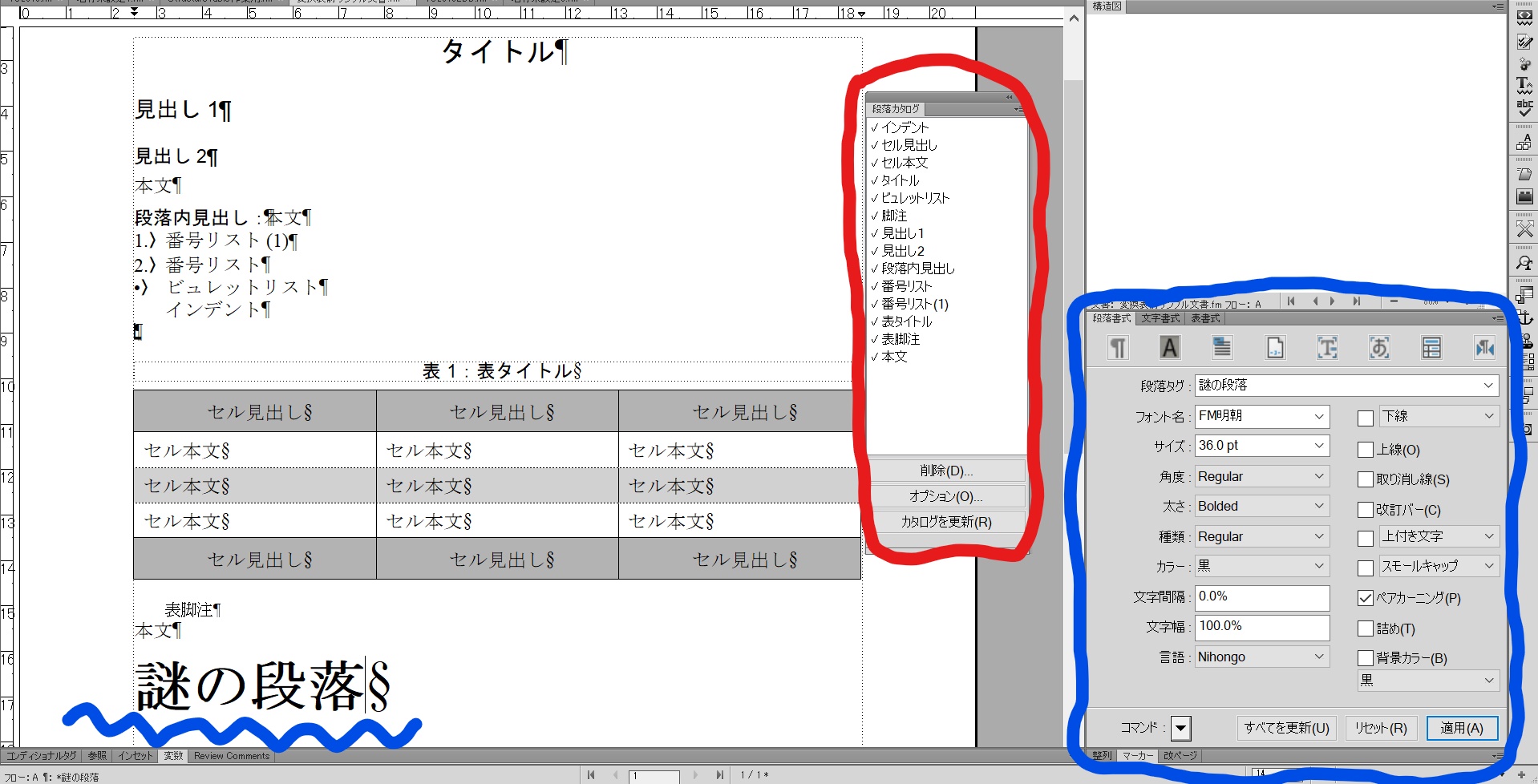
新規作成文書にデフォルトで作成される段落書式を文書に現わしたものですが、「謎の段落」という段落書式は登録されていないことがわかると思います。
この「謎の段落」という段落書式に対する対応も「変換表」には挿入されます。ファイルは以下です。
サンプル文書
逆に
FrameMaker は、文書をスキャンして、この文書中に出現する書式コンポーネントのリストを作成します。 リストには、書式設定カタログで定義されているが、文書では使われていないタグは含まれません。
FrameMaker (2017 release) ヘルプ から引用
ということで、書式が定義されているかどうかではなく、文書で使用されているかどうかが問われます。
ただ!!
むつかしく考えなくてもオッケーです。変換表は「更新」することが可能だからです。
ということでまずは、
- 「どちらかというと他の文書ファイルより色々な書式が使用されていそうな文書ファイル」を開きます。
サンプル文書に EDD からエレメント定義を取り込まなくても、とりあえず今は問題ありません。 - 構造/ユーティリティ/変換表を生成を選択し、「新しい変換テーブルを生成」を選択し、「生成」をクリックします。
メニューコマンドに関しては、バージョンで異なるので適宜読み替えてください。
変換表が生成されました。
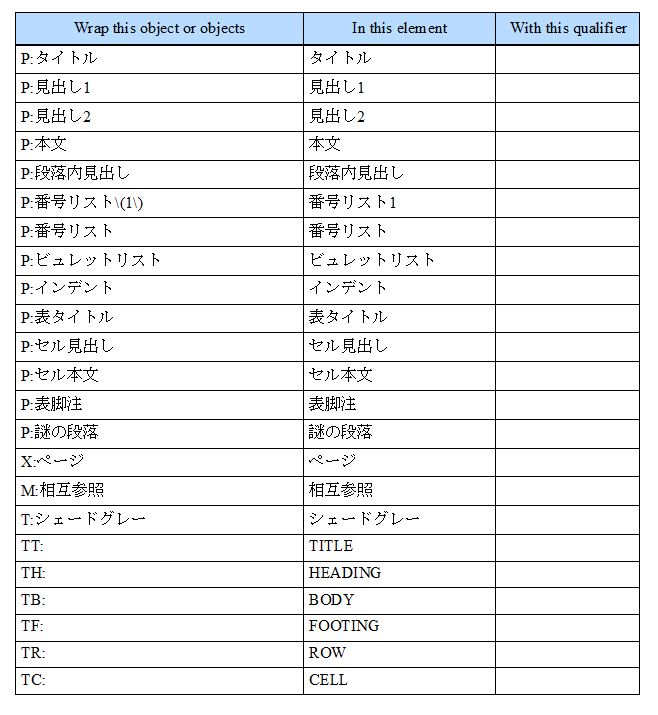
「Wrap this object or objects」列の元文書の内容を「In this element」列のエレメントでラップします。
「With this qualifier」列は、修飾子です。見分けるためのフラグ、グループ分け、ですね。「In this element」列のエレメントは同じでもグルーピングの種類が異なる場合に便利です。これをまた後でラップするわけです。
生成された表は3列ですが、変換表開発時に役に立つ4列目を追加しておきましょう。ヘッダは「Description」です。開発途中のメモ列として活用すると便利です。というかこの列が無いと、複雑な変換になったときにミスが起こりやすくなりますし、後から見たときにわかりやすくなります。
「In this element」列にはEDDで定義されたエレメントを記入するわけです。。。。
結局、すでにEDDが開発済みである必要がありますね。。。とはいえ、変換表の前半終了です。次回はやっぱりEDDに手を付けるのがよさそうでしょうか。。。